Git: A Quick Intro for Programmers
Git is a versioning system built on pointers.
Trees of pointers, like directories, keep track of files. Versions of files are stored in their entirety (not diffs). As files are created or changed, new trees are created to point to the new versions.
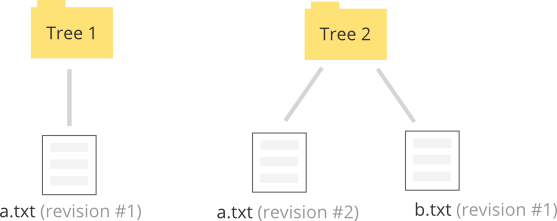
Trees can point to other trees, and together they can represent a snapshot of files at a certain point in time.
File changes are made with commits. A commit stores who made the change, when they made the change, a pointer to a tree (a group of file changes), and a pointer to the previous commit.
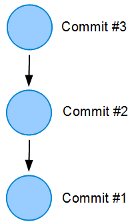
It is also possible for a single commit to point to two previous commits (a merge commit).
A tag is a pointer to a commit. A branch is like a tag but it moves over time, pointing to the latest commit. Branches are ways to keep track of diverging commits.
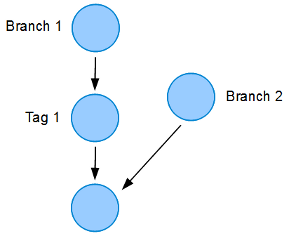
A git repository is basically a huge tree of commits, with branches and tags.
To work with a remote repository, you first clone the repository. Cloning copies down all of the files and each commit, along with any branches that exist on the server. You only clone once.
The default nickname for the server is origin. After you initially clone, you will only see origin (server) branches, and these branches are read-only. To make edits to origin branches, you first create a local branch, checkout the branch (switch to it), make commits to it, and then push your changes to an origin branch.
To get recent changes from others, you fetch commits from the server. Fetching gets the latest commits from the server and updates your origin (read-only) branch pointers. Your local branches are untouched, so this is a safe operation.
After fetching, your local branches will not be updated. You must merge from your now updated origin branch into your local branch.
A pull operation does a fetch, and then merges into your currently checked-out local branch. A pull is not a safe operation.
Leave a comment